
In my previous blog post I showed you how to create a cross account, cross region pipeline with CodePipeline. Today I’ll show you how to extend that pipeline so that your developers can have there own pipelines whilst also staying up to date on the latest changes.
First, a quick recap of the previous post. In the previous post we created a pipeline much like the following.
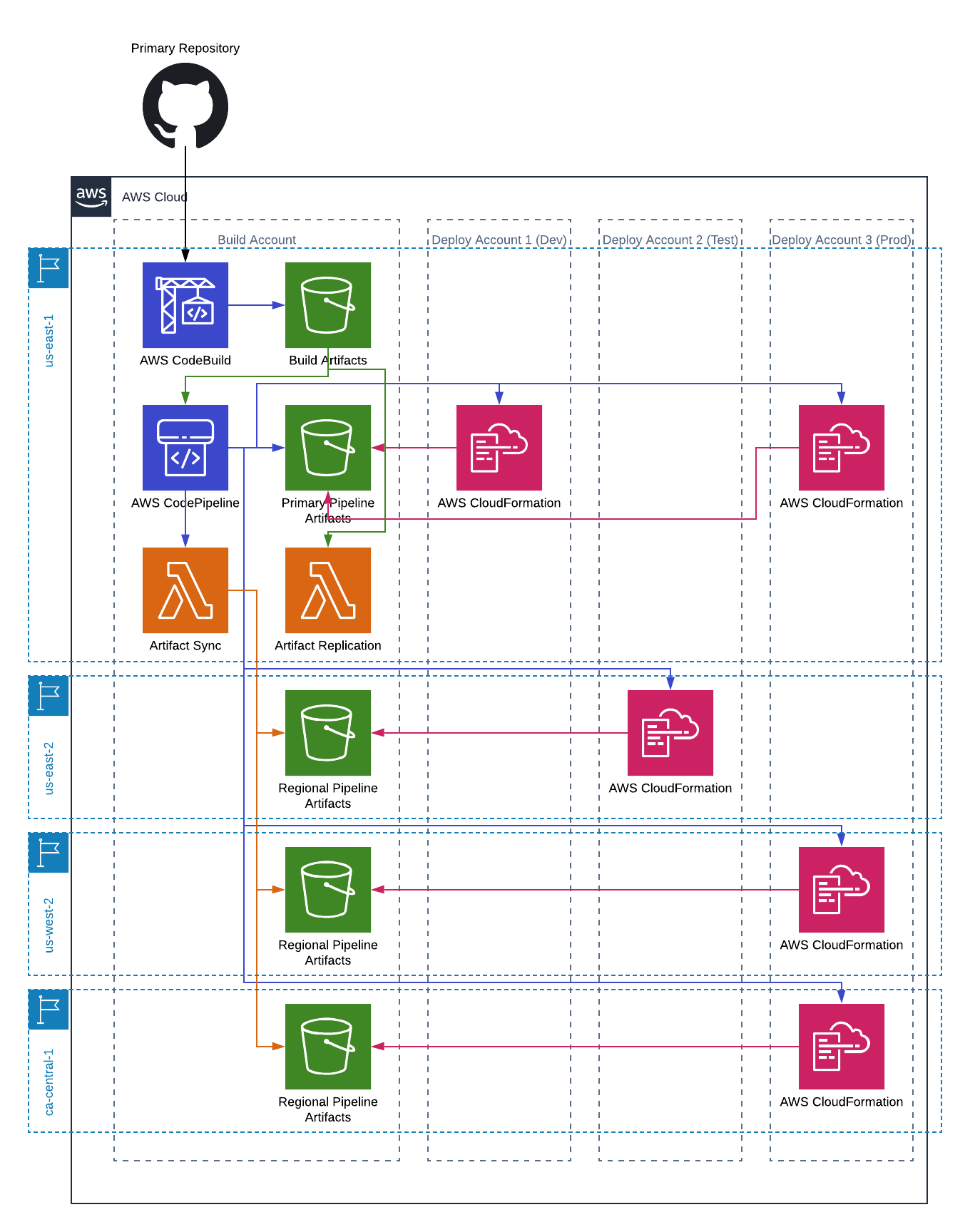
This pipeline allowed deployments to multiple AWS account and regions from a single place. Artifacts are built once and used throughout the process.
That did what we wanted; it allowed us to use CodePipeline for our DevOps practices. But we are developers; we always want more.
One of the great features we have at my current employer is the ability to create an AWS account for each developer. That account can run a full deployment of our application, acting just like the real thing. We use forks from the “real” repository to feed our developer account pipelines. This means that developers can test changes without impacting others, experiment in a safe place, and share changes without pushing to master. The most common issue we have is in keeping those accounts up to date.
The way we used to stay up to date (and still do for much of the code that hasn’t been moved to the new stack) was to merge in the upstream changes to the individual developer forks and push those changes to master. That would trigger a build in the developer’s AWS account, which would update their stack. As you might imagine, there are some significant drawbacks to this approach.
- As the number of repositories grows the number of forks that I need to merge keeps increasing.
- A developer could spend as much time merging changes as they spend making changes.
- This can also lead out of sync environments, which leads to invalid experimentation.
- The same code has to be built once for each developer account. Given that we are using CodeBuild (or, more importantly, build as code) this isn’t a huge issue, but as the organization grows the cost of doing this grows. Plus, it just feels better when the artifacts are the same everywhere.
On the first point, one could choose to point to the upstream repository instead of using a fork, but that makes it more difficult to make changes later, should you need to.
So, how do we change this?
Replicated Artifacts
The solution to the problem is actually pretty simple. Every time an artifact is created in the “real” build account you replicate the artifacts to any developer accounts. As a result each change in the “real” account leads to the same change being applied in the developer accounts. After all, all of our pipelines are triggered from an artifact in an S3 bucket.
If you want to make changes that don’t go to everyone you change the code in your fork, which kicks off a build in your account, puts artifacts in your build S3 bucket, and triggers the pipeline in your account. If you aren’t working on something, or even never work on some bit of code, the code will always be the same as what is in your dev environment (or whatever you deploy to from your build pipeline).
I’ve been asked about the case when two people are working in the same code. My first answer to this is stop doing that. In all seriousness, it may be a sign that your code is doing too much. This model works well in a true microservices architecture, but may not work well in more monolithic structures.
Making it happen
To make all this work we start by following the directions for creating a cross account, cross region pipeline from the previous post. In our case we will likely only do one account, and thus one region, but if a developer wanted to do more he/she could do so.
Once you have the basic framework in place you need to take some additional steps.
Developer Stack
The first additional step is to create a new stack using the ‘CrossAccountDeveloper.yaml`. This will create a bucket policy that will allow the “real” build account to access your developer build bucket.
Update the “Real” Build Account
Next, you’ll need to update the primary stack in the “real” build account. If you were looking closely at the CloudFormation template for this stack you may have noticed a few parameters that I haven’t talked about; EnableReplication, ReplicationBucketList, ReplicationBucketStarArns, ReplicationCMKs. You probably noticed a pattern here, they are all about replication. These are what need to be changed.
Obviously you’ll need to set EnableReplication to true. The ReplicationBucketList will be a comma separated list of the buckets to replicate to (if this is the first developer account it will just be the one bucket). The ReplicationBucketStarArns is the full arns with full access, again, comma separated. The ReplicationCMKs are the arns of the keys for each account you’re replicating to.
Easy button
Just like in the previous post, I’ve got an easier way to do this. Just run the developer.sh script, supply the requested values, and let it do the work. You’ll need to know the account and region of the “real” build account, the account and region of your developer account, and you’ll need a profile configured with access to each. The rest will be taken care of for you.
Once you’re done, you’ll have something that looks a lot like this:
